【Day13】實際操作 MCP Server 並透過 GitHub Copilot 繪製架構圖#
介紹#
既然已經簡單介紹了 MCP 的基本概念,接下來就是實際操作了,先從最簡單的開始,今天要介紹如何讓自己的 AI Agent 可以使用現成的 MCP Server。
操作#
如何執行 MCP Server#
開發的語言#
目前的 MCP Server 都是由 JavaScript、Node.js 或是 Python 來進行開發,另外也有使用 Docker 來封裝 MCP Server,這樣的好處是可以避免環境不相容的問題。
執行的指令與平常開發有何不同#
因爲 MCP Server 跟一般的開發不太一樣,像是 Node.js 可能會比較習慣使用 npm 或是 nvm 等指令來管理套件或是版本,但是 MCP Server 是一個獨立的應用程式,而且是希望可以直接執行的,所以大部份使用 Node.js 開發的 MCP Server 都會使用 npx 來執行。使用 npx 的好處是可以直接執行套件(執行完之後不會安裝在系統中),可以減少污染的問題。至於 Python 的部分,則是使用 uv 或是 uvx 都有,uv 主要是用來管理 Python 的虛擬環境,但是可以藉由 --with {package_name},讓程式執行的時候立刻安裝套件(一次性),避免污染系統。
MCP Server 的設定檔#
基本上 MCP Server 的設定檔都包含以下幾個部分:
command:執行的指令(npx、uv、uvx、docker)args:執行的參數env:環境變數
GitHub Copilot#
{
"servers": {
"github": {
"command": "docker",
"args": [
"run",
"-i",
"--rm",
"-e",
"GITHUB_PERSONAL_ACCESS_TOKEN",
"ghcr.io/github/github-mcp-server"
],
"env": {
"GITHUB_PERSONAL_ACCESS_TOKEN": "${input:github_token}"
}
}
}
}
Claude Code#
{
"mcpServers": {
"server-name": {
"command": "/path/to/server",
"args": [],
"env": {}
}
}
}
Codex#
[mcp_servers.server-name]
command = "npx"
args = ["-y", "mcp-server"]
env = { "API_KEY" = "value" }
# Optional: override the default 10s startup timeout
startup_timeout_ms = 20_000
實際使用 AWS Diagram MCP Server#
接下來我們就以 AWS Diagram MCP Server 來進行示範,這個 MCP Server 是讓 AI Agent 可以使用 diagrams 這個工具來繪製 AWS 架構圖。
{
"servers": {
"aws-diagram": {
"type": "stdio",
"command": "uvx",
"args": [
"awslabs.aws-diagram-mcp-server"
],
"env": {},
"cwd": "${workspaceFolder}"
}
},
"inputs": []
}
Prompt#
幫我繪製一個 AWS 架構圖
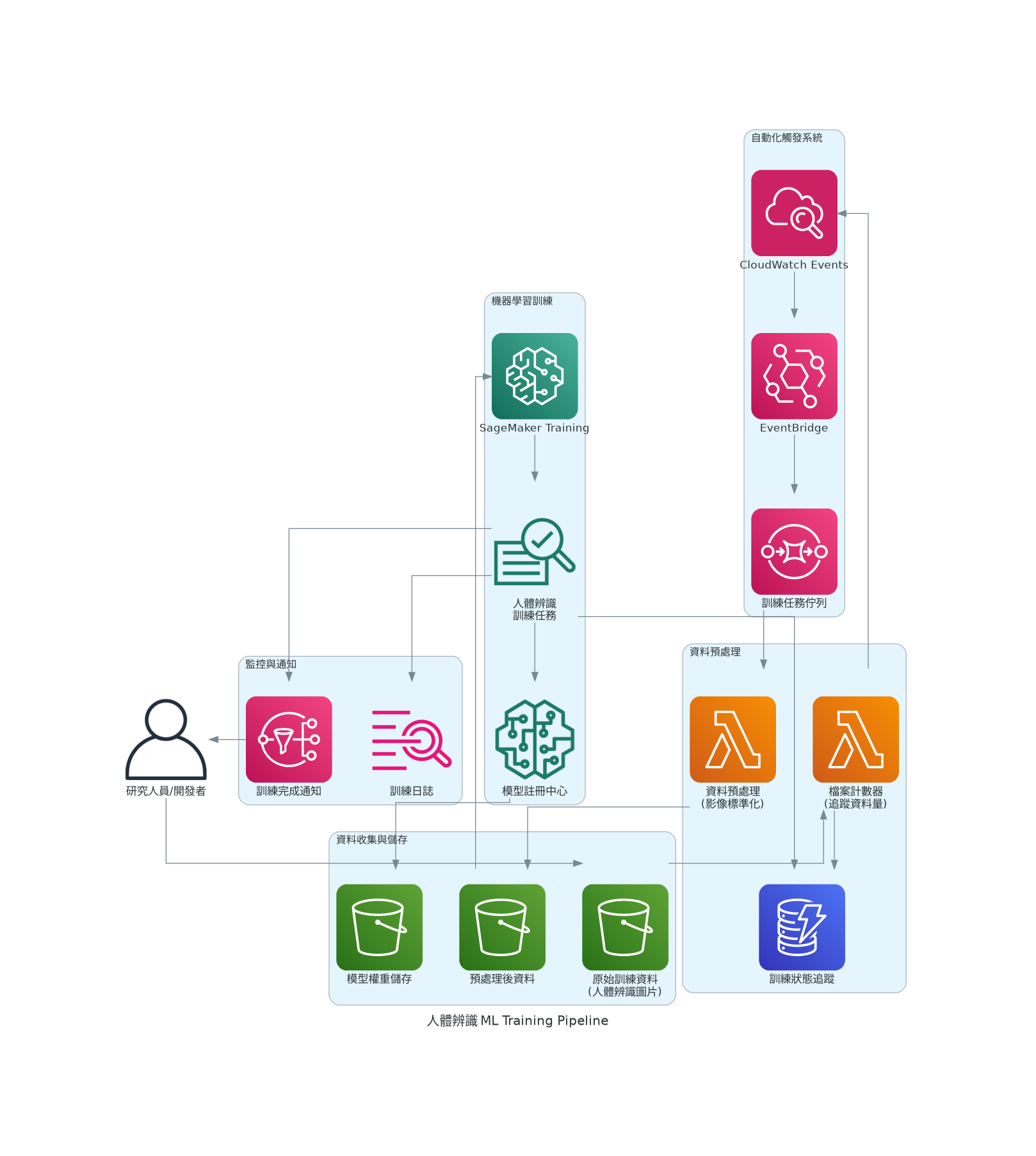
目的:在蒐集足夠訓練資料後,自動重新根據資料來調整/訓練模型
主要功能:
1. 使用 S3 來存放訓練資料(人體辨識)
2. 每當資料蒐集滿 1000 張,自動觸發訓練的 pipeline
3. 訓練完後,將模型權重存起來
目前我還不知道 AWS 哪些服務可以達成,請根據我的需求幫我完成整個架構設計,並告訴我每個服務的用處
實際產出#
讓我重新為你繪製人體辨識 ML Training Pipeline 的 AWS 架構圖: 太好了!我成功為你生成了完整的 AWS 機器學習 pipeline 架構圖。圖表已保存在 ml_training_pipeline.png。
## 🏗️ **AWS 架構設計說明**
### 📊 **各 AWS 服務的用途與功能**
#### **1. 資料收集與儲存層**
- **Amazon S3 (原始訓練資料)**: 儲存人體辨識的原始圖片,具有高可用性和無限擴展性
- **Amazon S3 (預處理後資料)**: 儲存經過標準化處理的訓練資料
- **Amazon S3 (模型權重儲存)**: 儲存訓練完成的模型權重和相關檔案
#### **2. 自動化觸發系統**
- **Amazon CloudWatch Events**: 監控 S3 事件,當檔案上傳時觸發
- **Amazon EventBridge**: 事件路由服務,協調不同服務間的通訊
- **Amazon SQS**: 訊息佇列,確保訓練任務的可靠執行和錯誤處理
#### **3. 資料預處理層**
- **AWS Lambda (檔案計數器)**:
- 追蹤 S3 中的檔案數量
- 當達到 1000 張圖片時觸發訓練流程
- 成本效益高,無需維護伺服器
- **AWS Lambda (資料預處理)**:
- 執行影像標準化(調整大小、格式轉換等)
- 資料清理和品質檢查
- **Amazon DynamoDB**:
- 追蹤訓練狀態和進度
- 儲存檔案計數和訓練歷史
#### **4. 機器學習訓練層**
- **Amazon SageMaker**:
- 完全託管的機器學習平台
- 自動擴展運算資源
- 支援多種深度學習框架(TensorFlow、PyTorch 等)
- **SageMaker Training Job**:
- 執行人體辨識模型訓練
- 支援分散式訓練和 GPU 加速
- **SageMaker Model Registry**:
- 模型版本管理
- 模型部署和回滾功能
#### **5. 監控與通知層**
- **CloudWatch Logs**: 記錄訓練過程中的所有日誌
- **Amazon SNS**: 訓練完成後發送通知給研究人員
## 🔄 **工作流程說明**
1. **資料上傳**: 研究人員將人體辨識圖片上傳到 S3
2. **自動計數**: Lambda 函數自動計算檔案數量並更新 DynamoDB
3. **觸發條件**: 當達到 1000 張圖片時,CloudWatch Events 觸發 EventBridge
4. **佇列處理**: 訓練任務被加入 SQS 佇列,確保可靠執行
5. **資料預處理**: Lambda 函數執行影像預處理並儲存到專用 S3 bucket
6. **模型訓練**: SageMaker 自動啟動訓練任務
7. **模型儲存**: 訓練完成的模型權重儲存到 S3 和 Model Registry
8. **通知完成**: 透過 SNS 通知研究人員訓練完成
## 💰 **成本優化特點**
- **無伺服器架構**: Lambda 和 SageMaker 按使用量計費
- **自動擴展**: 根據需求動態調整資源
- **儲存分層**: 使用 S3 的不同儲存類別優化成本
這個架構提供了完整的自動化 ML pipeline,能夠滿足你的所有需求!
補充說明:
雖然最後面 AI Agent 成功產出架構圖,但是筆者總共試了 2 種執行 MCP Server 的方法(
uvx以及docker),使用體驗不是特別好(總步數 20 多步才出繪製成功)。在使用 Docker 的時候,中間卡在 mcp server 是在 docker 裏面執行,雖然有把當前的工作目錄掛載進去,但是 AI Agent 最後在存檔的時候還是不停搞錯路徑(要把 docker 內的圖片 cp 出來,但是 cp 的指令是在容器外執行,就是頗麻煩,還要去確認容器的工作目錄)。最後是透過在本機端強制安裝套件,再把檔案匯出成 png 檔案,才成功的把圖片存下來。
重點回顧#
介紹 GitHub Copilot、Claude Code、Codex 三個 MCP Server 的設定方式(2 個 Json、1 個 toml)
實際操作 AWS Diagram MCP Server,讓 AI Agent 可以繪製 AWS 架構圖(發現一些存取路徑的問題)